etcd raft 라이브러리 사용해보기
- 원본: 원본글 바로가기
- 이전 시리즈: etcd raft 모듈 분석해보기
TOC
서론
복학하기 전에 간단하게 진행할 프로젝트를 찾고 있다가 build-your-own-redis를 보고 golang으로 따라서 만들어보는 계획을 세웠습니다. 문서를 참고하며 RESP v2(Redis Serialization Protocol)를 파싱해보고 간단한 TTL을 구현하는 등의 작업을 진행했습니다. 이후 아쉬움이 남아 고민하던 중에 2년전 etcd-raft 모듈을 분석했던 글이 생각났습니다. 그래서 ‘이번엔 직접 사용해볼까?’하는 생각으로 기초적인 기능만 구현해놓은 godis(redis를 모방한 무언가)에 raft를 이용한 복제 기능을 추가해보았습니다.
구현 코드는 대부분 etcd-raftexample을 참고했습니다. 그래서 코드를 어떻게 작성해야하는지 보다는 각 코드가 갖는 의미를 풀어내는 방식으로 작성했습니다. 혹시라도 나중에 etcd-raft 모듈을 사용하게 될 분들께 도움이 됐으면 좋겠습니다.
또 1편에서 건너뛰었던 Snapshot 처리 부분을 이 글에서 정리했습니다.
현재 etcd 레포에서 raft는 삭제되었고 별도 레포로 독립했습니다. 기존 raftexample은 etcd의 코드들(rafthttp, wal…)에 의존하고있어서 새로운 독립적인 example을 만드는 중인 것 같습니다. etcd-issues-14713, raft-issues-2.
ChatGPT님는 알고있을까요?
먼저 etcd raft 모듈을 사용해서 분산 데이터베이스를 만드는 방법을 질문해봤습니다.

대답이 애매모호해서 예시 코드를 요청해봤습니다.

오…?
2번째 질문에서 ChatGPT가 제공해준 코드 전체.
package main
import (
"flag"
"log"
"net"
"net/http"
"net/rpc"
"os"
"github.com/coreos/etcd/raft"
"github.com/coreos/etcd/raft/raftpb"
)
type KeyValueStore struct {
store map[string]string
}
func (kv *KeyValueStore) Get(key string, value *string) error {
*value = kv.store[key]
return nil
}
func (kv *KeyValueStore) Set(key string, value string, success *bool) error {
kv.store[key] = value
*success = true
return nil
}
func main() {
var (
id = flag.Int("id", 0, "node ID")
peers = flag.String("peers", "", "comma separated list of peers")
join = flag.Bool("join", false, "join an existing cluster")
storage = flag.String("storage", "", "path to persistent storage")
)
flag.Parse()
store := &KeyValueStore{
store: make(map[string]string),
}
// Create Raft node configuration
cfg := &raft.Config{
ID: uint64(*id),
ElectionTick: 10,
HeartbeatTick: 1,
Storage: raft.NewMemoryStorage(),
MaxSizePerMsg: 4096,
MaxInflightMsgs: 256,
}
// Create transport layer
transport, err := raft.NewTCPTransport(":7000", nil, 3, 10*time.Second, os.Stderr)
if err != nil {
log.Fatalf("Error creating transport layer: %v", err)
}
// Create Raft node
node, err := raft.NewNode(cfg, store, transport, nil, nil)
if err != nil {
log.Fatalf("Error creating Raft node: %v", err)
}
// Add peers to node if joining an existing cluster
if *join {
var err error
var addrs []string
for _, addr := range strings.Split(*peers, ",") {
addrs = append(addrs, addr)
}
node.JoinCluster(addrs)
}
// Start the node
node.Start()
// Serve HTTP requests
kv := &KeyValueStore{
store: make(map[string]string),
}
rpc.Register(kv)
rpc.HandleHTTP()
l, err := net.Listen("tcp", ":8000")
if err != nil {
log.Fatalf("Error listening: %v", err)
}
go http.Serve(l, nil)
// Wait for node to exit
<-node.ApependEnts()
// Stop the node
node.Stop()
}
마지막에는 코드 동작 설명까지 해주는 친절한 모습..

거짓말이 많긴 하지만 전달인자로 id, peers 정보를 받는 부분과 raft.Config를 사용하는 부분은 정말 아는게 아닌가? 하고 착각할 정도로 정확해서 깜짝 놀랬습니다.
그래도 아직 ChatGPT님이 정확한 정보를 제공해주지 않으니 제가 이 글을 쓰는데 의미가 있는 것 같습니다.
godis
간단하게 복제 기능을 붙일 godis에 대해 살펴보겠습니다.
godis는 RESP v2 프로토콜을 사용하고 다음과 같이 set, get, mget 3개의 string commands만 지원합니다. 나름 set은 redis에서 제공하는 모든 옵션(ex, exat, get, keepttl 등)을 동일하게 처리하도록 구현했습니다. list commands까지는 추가하려는 의지가 있었지만 raft를 추가하는 바람에 우선순위가 밀렸습니다.

우선 다음과 같이 최소한의 읽기, 쓰기 기능을 지원하기 때문에 바로 etcd-raft를 이용한 복제 기능 구현에 들어가보겠습니다.
bootstrap
readme 문서에도 나와있는 것처럼 raft.StartNode, raft.RestartNode을 통해 raft.Node 객체를 생성해야 한다. 이때 노드의 bootstrap 상태에 따라 peers를 넘겨주느냐(StartNode), 안넘겨주느냐(RestartNode)를 선택한다.
etcd의 경우
etcd는 다음과 같이 3가지 경우로 나눠 raft.Node 객체를 생성한다.
- wal(X) & init cluster(X) -> restartNode
- 기존 클러스터에 새로 join하는 형태의 노드
- wal(X) & init cluster(O) -> startNode
- 새로운 클러스터를 구성하는 형태의 노드
- wal(O) -> restartNode
- 이전에 실행됐었던 기록이 있는 형태의 노드
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/server/etcdserver/bootstrap.go#L473
func bootstrapRaft(cfg config.ServerConfig, cluster *bootstrapedCluster, bwal *bootstrappedWAL) *bootstrappedRaft {
switch {
case !bwal.haveWAL && !cfg.NewCluster:
// WAL이 없고 새로운 클러스터를 초기화하는 것도 아님 -> 기존 클러스터에 새롭게 join 하는 노드
// peers를 비움 -> restartNode
return bootstrapRaftFromCluster(cfg, cluster.cl, nil, bwal)
case !bwal.haveWAL && cfg.NewCluster:
// WAL이 없고 새로운 클러스터를 초기화함 -> 새로운 클러스터를 구성하는 노드
// peers를 전달 -> startNode
return bootstrapRaftFromCluster(cfg, cluster.cl, cluster.cl.MemberIDs(), bwal)
case bwal.haveWAL:
// WAL이 있음 -> 충돌 or 중단되었다가 재시작하는 노드
// peers를 비움 -> restartNode
return bootstrapRaftFromWAL(cfg, bwal)
default:
cfg.Logger.Panic("unsupported bootstrap config")
return nil
}
}
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/server/etcdserver/bootstrap.go#L487
func bootstrapRaftFromCluster(cfg config.ServerConfig, cl *membership.RaftCluster, ids []types.ID, bwal *bootstrappedWAL) *bootstrappedRaft {
// ...
peers := make([]raft.Peer, len(ids))
// ...
return &bootstrappedRaft{
// ...
peers: peers,
// ...
}
}
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/server/etcdserver/bootstrap.go#L537
func (b *bootstrappedRaft) newRaftNode(ss *snap.Snapshotter, wal *wal.WAL, cl *membership.RaftCluster) *raftNode {
var n raft.Node
if len(b.peers) == 0 {
n = raft.RestartNode(b.config)
} else {
n = raft.StartNode(b.config, b.peers)
}
// ...
}
내 구현
godis의 경우 다음과 같이 실행하도록 계획했다.
- 처음 새로운 클러스터를 생성하는 경우
initial-cluster에 클러스터에 참가하는 모든 peers를 id와 함께 입력받는다.
- 기존 클러스터에 참가하거나 재시작하는 경우
discovery에 기존 클러스터에 참가해있는 peers의 일부를 입력받는다.
# godis cluster --id 1 \
--listen-client http://0.0.0.0:6379 \
--listen-peer http://127.0.0.1:6300 \
--initial-cluster 1@http://127.0.0.1:6300,2@http://127.0.0.1:16300,3@http://127.0.0.1:26300 \
--waldir /some/wal/dir --snapdir /some/snap/dir
# godis cluster --id 4 \
--listen-client http://0.0.0.0:6382 \
--listen-peer http://127.0.0.1:36300 \
--discovery http://127.0.0.1:6300,http://127.0.0.1:16300 \
--join \
--waldir /some/wal/dir --snapdir /some/snap/dir
먼저 wal이 있는지 확인하고, 만약 wal이 있다면 복제 로그에 반영한다.
새로운 클러스터를 초기화하는 경우 전달인자로 받은 peers를 기반으로 raft.Node를 생성한다. 만약 재시작하거나 새로 참가하는 경우 discovery를 기반으로 peers 점보를 얻고 raft.Node를 생성한다.
func (rn *raftNode) start(initialCluster, discovery []string) {
// 새로운 클러스터를 생성할 때
// initialCluster : 1@http://127.0.0.1:6300,2@http://127.0.0.1:16300,3@http://127.0.0.1:26300
// discovery : empty
// 재시작하거나 기존 클러스터에 참가할 때
// initialCluster : empty
// discovery : http://127.0.0.1:6300,http://127.0.0.1:16300
walExists := wal.Exist(rn.walDir)
rn.wal = rn.openWAL(rn.walDir)
rn.raftStorage = raft.NewMemoryStorage()
if walExists {
rn.replayWAL(rn.raftStorage)
}
// ...
if walExists || rn.join {
rn.discoverCluster(discovery)
rn.node = raft.RestartNode(cfg)
} else {
rn.initPeers(initialCluster)
rpeers := make([]raft.Peer, 0)
rn.peers.Range(func(pid, _ any) bool {
rpeers = append(rpeers, raft.Peer{ID: uint64(pid.(int))})
return true
})
rn.node = raft.StartNode(cfg, rpeers)
}
// ...
}
Transport Peers
peers간 raft.Message를 주고 받는 Transport 계층은 etcd-io/etcd/server/etcdserver/api/rafthttp을 그대로 가져와서 사용했다. 기본 heartbeat, 복제 로그, 스냅샷을 알아서 잘 깔끔하게 처리해주기 때문에 굳이 직접 구현할 필요가 없었다.
한가지 주의해야 할 점은 rafthttp.Transport의 peers와 raft.Node의 peers를 동기화해야 한다는 것이다.
우선 전달인자로 받은 initialCluster이나 discovery를 통해 얻은 peers 정보를 기반으로 Transport에 peers를 추가한다.
func (rn *raftNode) start(initialCluster, discovery []string) {
// ...
rn.peers.Range(func(pid, purl any) bool {
if pid.(int) != rn.id {
rn.transport.AddPeer(types.ID(pid.(int)), []string{purl.(string)})
}
return true
})
// ...
}
이후 ConfChange로 인해 추가/제거되는 peers도 Transport에 반영해준다.
func (rn *raftNode) serveChannels() {
// ...
for {
select {
case <-ticker.C:
rn.node.Tick()
case rd := <-rn.node.Ready():
// ...
applyDoneCh, ok := rn.publishEntries(rn.entriesToApply(rd.CommittedEntries))
// ...
case <-rn.transport.ErrorC:
return
case <-rn.ctx.Done():
return
}
}
}
func (rn *raftNode) publishEntries(ents []raftpb.Entry) (<-chan struct{}, bool) {
// ...
for i := range ents {
switch ents[i].Type {
case raftpb.EntryNormal:
// ...
case raftpb.EntryConfChange: // Committed ConfChange를 Transport에 반영
var cc raftpb.ConfChange
cc.Unmarshal(ents[i].Data)
rn.confState = *rn.node.ApplyConfChange(cc)
switch cc.Type {
case raftpb.ConfChangeAddNode:
if len(cc.Context) > 0 {
// ...
rn.transport.AddPeer(types.ID(cc.NodeID), []string{string(cc.Context)})
rn.peers.Store(int(cc.NodeID), string(cc.Context))
}
case raftpb.ConfChangeRemoveNode:
// ...
rn.transport.RemovePeer(types.ID(cc.NodeID))
rn.peers.Delete(int(cc.NodeID))
}
rn.w.Trigger(cc.ID, nil)
}
}
// ...
}
조금더 유심히 살펴봐야하는 부분은 ConfChange 부분이다.
godis raft 구현 초기에는 기존 클러스터에 참가하는 노드의 경우에도 처음 클러스터를 구성했던 노드들의 정보(initialCluster)만 주면 ConfChange가 알아서 복제되면서 Transport의 peers를 raft의 peers와 동기화할 수 있을 것이라 생각했다. 하지만 스냅샷 생성 이후 복제 로그가 압축된 경우에 ConfChange는 새로 참가한 노드로 전달되지 않는 문제가 있었다.

위 상황에서 Node5는 Node4의 ConfChangeAddNode를 받지 못한다. 만약 Node5를 initialCluster=Node1,Node2,Node3으로 실행한다면 Transport에 Node4를 추가할 방법이 없다. 따라서 rafthttp.Transport의 peers를 잘 관리하려면 discovery 서비스를 통해 Node4를 찾거나 스냅샷을 생성할때 ConfChange 정보를 포함시키는 등의 작업이 필요하다.
raft main loop
etcd-raft 모듈을 사용할때 가장 중요한 작업은 모듈 내부에서 전달해주는 ready를 잘 처리하는 것이다. 이 부분의 구현에 따라 CommittedEntries가 Storage에 적용되는 흐름과 스냅샷이 생성/적용되는 흐름이 달리지기 때문에 요구사항을 잘 판단해서 구현해야 한다.
etcd의 경우
아래는 실제 etcd가 ready를 처리하는 코드이다. etcd-raft readme 문서에서는 알려주지 않았던 작업들이 몇가지 있다.
notifyc를 통해 스냅샷이 디스크에 저장 작업과 Entries 적용 등의 작업을 동기화시키는 부분- 리더일 때와 리더가 아닐 때 달라지는 raftpb.Message 전송(transport.Send) 시점
주석으로 정리해 보았는데 여러번 읽어야 조금 이해가 가는 듯 하다. notifyc 채널의 크기를 1로 설정해두고 여러 작업의 흐름을 제어하는 코드가 인상적이다.
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/server/etcdserver/raft.go#L158
func (r *raftNode) start(rh *raftReadyHandler) {
internalTimeout := time.Second
go func() {
defer r.onStop()
islead := false
for {
select {
case <-r.ticker.C:
r.tick()
case rd := <-r.Ready():
// 0. 리더 확인
if rd.SoftState != nil {
// rd.SoftState를 읽어서
// 리더가 있는지, 리더가 누구인지 확인
}
if len(rd.ReadStates) != 0 {
// 안전한 read index 전달
}
// 1. CommittedEntries, Snapshot을 적용하는 곳으로 전달하여 병렬로 처리
notifyc := make(chan struct{}, 1) // applySnapshot(만약 있으면), triggerSnapshot 처리에 블락을 검
ap := apply{
entries: rd.CommittedEntries,
snapshot: rd.Snapshot,
notifyc: notifyc,
}
updateCommittedIndex(&ap, rh)
select {
case r.applyc <- ap:
case <-r.stopped:
return
}
// 2. 리더는 CommittedEntries, Snapshot 반영 작업이 끝나지 않아도 로그 복제를 진행할 수 있도록 함
if islead {
r.transport.Send(r.processMessages(rd.Messages))
}
// 3-1. 스냅샷 복원후에 노드를 복구할 수 있도록 HardState, Entries보다 먼저 Snapshot 저장
if !raft.IsEmptySnap(rd.Snapshot) {
if err := r.storage.SaveSnap(rd.Snapshot); err != nil {
r.lg.Fatal("...")
}
}
// 3-2. HardState, Entries 저장
if err := r.storage.Save(rd.HardState, rd.Entries); err != nil {
r.lg.Fatal("...")
}
// ...
// 4. 스냅샷 적용
if !raft.IsEmptySnap(rd.Snapshot) {
// ...
// 스냅샷을 저장했으니(SaveSnap) applySnaphost에서 스냅샷을 적용할 수 있도록 블락을 품
notifyc <- struct{}{}
// 복제 로그에 스냅샷 상태 적용
r.raftStorage.ApplySnapshot(rd.Snapshot)
// 최신 스냅샷 이전의 WAL을 정리
if err := r.storage.Release(rd.Snapshot); err != nil {
r.lg.Fatal("...")
}
}
// 5. 복제 로그에 Entries 추가
r.raftStorage.Append(rd.Entries)
// 6. 리더가 아닌 경우
if !islead {
msgs := r.processMessages(rd.Messages)
// triggerSnapshot을 처리할 수 있도록 블락을 품
notifyc <- struct{}{}
// !! CommittedEntries에 ConfChange가 있다면 모두 적용될 때까지 raftpb.Message를 전송하면 안됨
waitApply := false
for _, ent := range rd.CommittedEntries {
if ent.Type == raftpb.EntryConfChange {
waitApply = true
break
}
}
if waitApply {
// 만약 applyAll에서 applyEntries를 처리하고 있다면 앞선 'notifyc <- struct{}{}'애 의해 채널이 꽉찬 상태임
// 여기서 다시한번 'notifyc <- struct{}{}' 한다면 applyAll에서 applyEntries를 끝낼 때까지 기다리게 됨
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/server/etcdserver/server.go#L909
select {
case notifyc <- struct{}{}:
case <-r.stopped:
return
}
}
// Snapshot, ConfChange를 모두 적용한 뒤에 raftpb.Message 전송
r.transport.Send(msgs)
} else {
// triggerSnapshot을 처리할 수 있도록 블락을 품
notifyc <- struct{}{}
}
r.Advance()
case <-r.stopped:
return
}
}
}()
}
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/server/etcdserver/server.go#L899
// raft main loop에서 전달받은 apply를 처리하는 로직
func (s *EtcdServer) applyAll(ep *etcdProgress, apply *apply) {
s.applySnapshot(ep, apply) // 여기서도 스냅샷이 디스크에 저장될 때가지 대기함(<-apply.notifyc).
s.applyEntries(ep, apply)
// ...
// raft main loop에서 블락을 풀어줄 떄까지 대기
<-apply.notifyc
s.triggerSnapshot(ep) // entries가 많이 쌓였으면 스냅샷 생성
select {
case m := <-s.r.msgSnapC:
merged := s.createMergedSnapshotMessage(m, ep.appliedt, ep.appliedi, ep.confState)
s.sendMergedSnap(merged)
default:
}
}
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/server/etcdserver/server.go#L921
func (s *EtcdServer) applySnapshot(ep *etcdProgress, apply *apply) {
if raft.IsEmptySnap(apply.snapshot) { // 스냅샷이 없다면 넘어감
return
}
// ...
// 스냅샷이 디스크에 저장될 때까지 대기
<-apply.notifyc
// 스냅샷 적용
}
내 구현
etcd에 비해서 너무 초라해 보이지만 필요한 작업은 모두 있다.
Snapshot 적용을 위해 외부로 전달하는 코드는(rn.publishSnapshot) Snapshot이 디스크에 저장되고(rn.saveSnap) 나서 실행되기 때문에 raftexample은 따로 동기화해줄 필요가 없었다.
CommittedEntries가 모두 적용된 이후에 triggerSnapshot이 처리되도록 applyDoneCh를 raftexample이 사용했다.
raftpb.Message를 전송하는 시점 raftexample에서는 rn.publishEntries(...) 이전이었지만 godis에서는 이후에 실행되도록 수정했다.
func (rn *raftNode) serveChannels() {
// ...
for {
select {
case <-ticker.C:
rn.node.Tick()
case rd := <-rn.node.Ready():
if !raft.IsEmptySnap(rd.Snapshot) {
rn.saveSnap(rd.Snapshot)
}
rn.wal.Save(rd.HardState, rd.Entries)
if !raft.IsEmptySnap(rd.Snapshot) {
rn.raftStorage.ApplySnapshot(rd.Snapshot)
rn.publishSnapshot(rd.Snapshot)
}
rn.raftStorage.Append(rd.Entries)
applyDoneCh, ok := rn.publishEntries(rn.entriesToApply(rd.CommittedEntries))
if !ok {
return
}
rn.transport.Send(rn.processMessage(rd.Messages)) // publishEntries에서 ConfChange는 모두 처리했으므로 바로 전송해도 됨
rn.maybeTriggerSnapshot(applyDoneCh)
rn.node.Advance()
case <-rn.transport.ErrorC:
return
case <-rn.ctx.Done():
return
}
}
}
func (rn *raftNode) publishEntries(ents []raftpb.Entry) (<-chan struct{}, bool) {
// CommittedEntries에서 ConfChange는 바로 Transport에 적용시키고
// EntryNormal만 따로 모아서 Storage 쪽으로 보냄
// ...
for i := range ents {
switch ents[i].Type {
case raftpb.EntryNormal:
// ...
case raftpb.EntryConfChange:
// ...
switch cc.Type {
case raftpb.ConfChangeAddNode:
if len(cc.Context) > 0 {
rn.transport.AddPeer(types.ID(cc.NodeID), []string{string(cc.Context)})
rn.peers.Store(int(cc.NodeID), string(cc.Context))
}
case raftpb.ConfChangeRemoveNode:
if cc.NodeID == uint64(rn.id) {
return nil, false
}
rn.transport.RemovePeer(types.ID(cc.NodeID))
rn.peers.Delete(int(cc.NodeID))
}
// ...
}
}
// ...
}
func (rn *raftNode) maybeTriggerSnapshot(applyDoneCh <-chan struct{}) {
if rn.appliedIndex-rn.snapshotIndex <= rn.snapCount {
return
}
if applyDoneCh != nil {
select {
case <-applyDoneCh:
case <-rn.ctx.Done():
return
}
}
// ...
}
write request
쓰기 요청을 처리하는 것은 너무 명백하다. node.Propose를 통해 복제할 데이터를 전달하고 raft main loop에서 ready.CommittedEntries를 읽어서 Storage에 반영하면 된다.
문제는 node.Propose와 ready.CommittedEntries를 처리하는 시점이 동기화되어있지 않다는 것이다.
만약 복제가 모두 이뤄지지 않은 상태에서 클라이언트에게 성공 응답을 보낼 경우 요청이 안전하게 처리되는 것을 보장할 수 없다. raftexample은 propose만 처리하고 바로 성공 응답을 보내버린다. 물론 성능과 trade-off 관계라서 요구사항을 잘 따져보고 선택해야 하는 부분이긴 하다. kafka의 경우에는 ack 옵션을 통해 성공 응답을 보내는 시점을 선택할 수 있다.
나는 쓰기 요청에 대한 응답을 로그가 커밋되는 시점(quorum만큼 복제된 시점)에 보내는 것으로 계획했기 때문에 두 작업을 동기화 시킬 필요가 있었다. 그림으로 표현하면 다음과 같다.
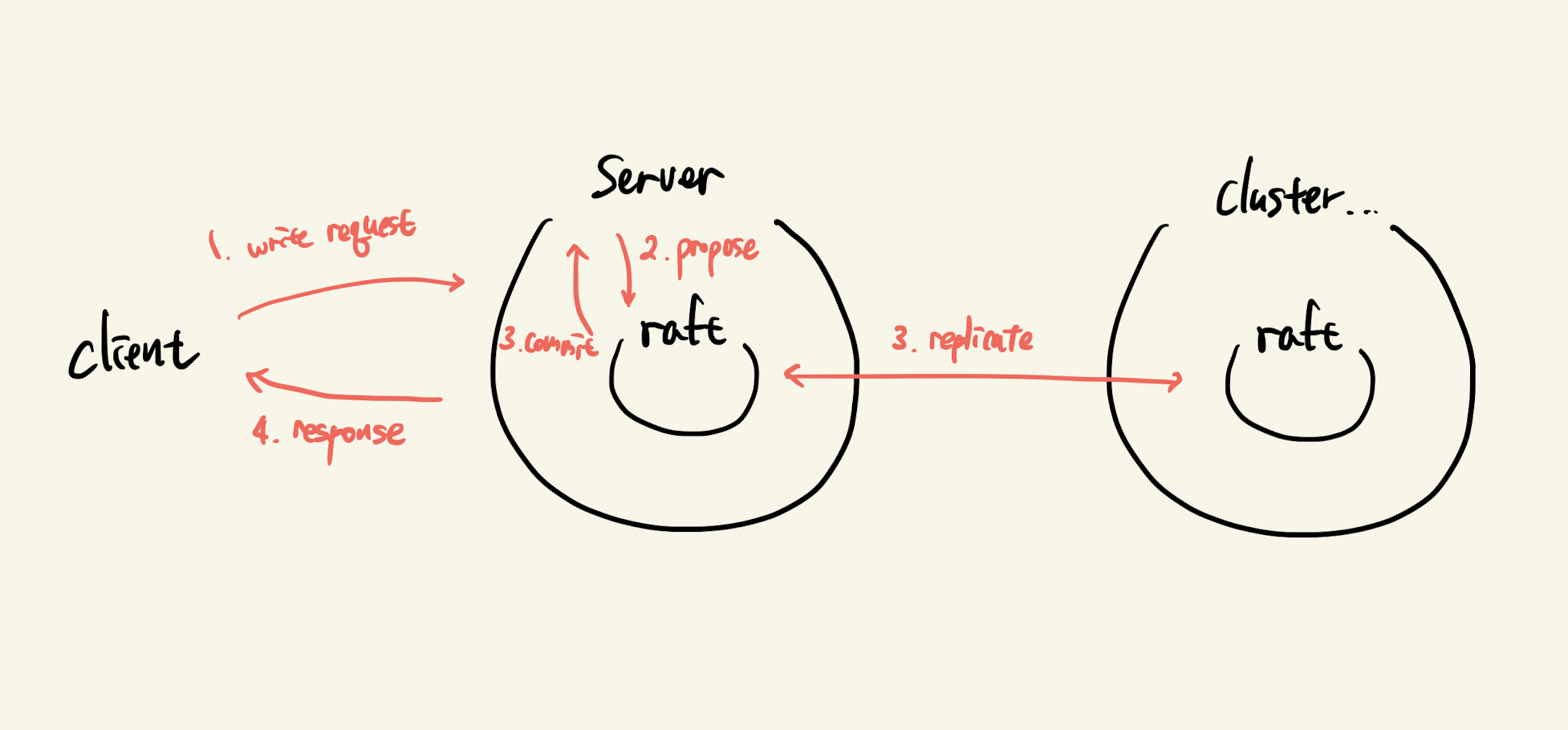
propose와 wait
node.Propose는 클라이언트 요청 핸들러 고루틴에서 실행되고 ready.CommittedEntries는 다른 처리 고루틴에서 처리되기 때문에 채널을 통해 두 작업을 동기화 해야 한다.
정말 감사하게도 etcd는 etcd-io/etcd/pkg/wait 패키지에 해당 기능을 구현해놓았다. 기능은 Wait, WaitTime이 있다.
- Wait: 특정 식별자로 대기를 걸고, 식별자만 타겟팅해서 대기를 풀 수 있는 기능
- WaitTime: 논리적 시각(deadline)으로 대기를 걸고, 특정 시각 이전의 모든 대기를 풀 수 있는 기능
커밋된 요청을 처리하는 고루틴은 해당 작업을 요청한 고루틴에게만 결과를 전달해야하기 때문에 동기화 작업에는 Wait를 사용했다.
// 클라이언트 요청을 처리하는 고루틴에서 호출
func (a *clusterApplier) processWriteCommand(ctx context.Context, cmd command.WriteCommand) (resp.Reply, error) {
id := a.idGen.Next() // 클러스터 내에서 유일한 식별자 생성
d, _ := command.Marshal(cmd)
req := raftRequest{
ID: id,
Data: d,
}
var buf bytes.Buffer
gob.NewEncoder(&buf).Encode(req)
a.proposeCh <- buf.Bytes() // node.Propose
ch := a.w.Register(id) // id 식별자로 대기
cctx, cancel := context.WithTimeout(ctx, time.Second)
defer cancel()
select {
case r := <-ch: // commit되고 storage에 반영될 때까지 대기
// ...
return r.(resp.Reply), nil
case <-cctx.Done():
a.w.Trigger(id, nil) // 작업 취소
return nil, errors.New("propose timeout")
}
}
// CommittedEntries를 처리하는 고루틴
func (a *clusterApplier) applyCommits() {
// ...
for commit := range a.commitCh { // ready.CommittedEntries without ConfChange
// ...
for _, ent := range commit.ents {
a.applyCommit(ent.Data)
}
// ...
}
}
func (a *clusterApplier) applyCommit(d []byte) {
var req raftRequest
err := gob.NewDecoder(bytes.NewBuffer(d)).Decode(&req)
// ...
cmd, err := command.Unmarshal(req.Data)
// ...
reply := a.applier.Apply(context.TODO(), cmd) // CommittedEntry 처리
if a.w.IsRegistered(req.ID) { // 해당 로그를 propose한 노드인 경우 Wait에 등록되어 있음
a.w.Trigger(req.ID, reply) // 대기하고 있는 채널로 실행 결과를 보냄
}
}
follower handle write request
follower 상태의 노드가 쓰기 요청을 처리하는 것이 의미상으로 이상할 수 있다.
실제로 follower 상태의 서버가 읽기 요청만 처리해야 한다면 자신의 raft.Node 상태를 확인해서 쓰기 요청시에는 실패 응답을 보내도록 구현하면 된다. 그냥 구현의 영역이기 때문에 요구사항에 따라 선택하면 된다.
나는 raft 모듈이 제공해주는 Internal proposal redirection from followers to leader 기능을 사용해서 클라이언트 입장에선 follower도 쓰기 요청을 처리하는 것 처럼 보이도록 구현했다. 하지만 내부적으로는 리더로 요청이 redirection되고 리더가 요청을 처리하는 형태로 수행한다. 그림으로 정리하면 다음과 같다.

read request
읽기 요청을 처리하는 부분도 그냥 요구사항에 따라 알아서 구현하면 된다. Storage 계층의 구현에 따라 달라지는 것 같다.
CommittedEntry.Index를 기반으로 multi version record 형태의 Storage를 관리한다면 최신 appliedIndex를 활용해서 읽을 수 있을 것 같다.
godis에는 그런건 없기 때문에 그냥 바로 Storage에 접근해서 읽기 요청을 처리한다.
slow follower
etcd-raft readme 문서에는 다음과 같이 안전한 읽기를 위한 기능이 있다고 소개한다.
## Features
- Efficient linearizable read-only queries served by both the leader and followers
- leader checks with quorum and bypasses Raft log before processing read-only queries
- followers asks leader to get a safe read index before processing read-only queries
실제로 slow follower의 경우 committedIndex보다 appliedIndex가 뒤쳐져 있을 가능성이 크다. 이 경우 아무런 확인 작업 없이 Storage에 접근해서 읽기 요청을 처리하면 잘못된 레코드를 읽어 응답할 수 있다. raft-etcd는 이러한 상황을 위해서 quorum을 만족하는 index를 확인할 수 있는 기능을 제공한다.
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/raft/node.go#L560
func (n *node) ReadIndex(ctx context.Context, rctx []byte) error {
return n.step(ctx, pb.Message{Type: pb.MsgReadIndex, Entries: []pb.Entry{{Data: rctx}}})
}
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/raft/node.go#L52
type Ready struct {
// ...
ReadStates []ReadState
// ...
}
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/raft/read_only.go#L24
type ReadState struct {
Index uint64 // safe read index
RequestCtx []byte // ReadIndex
}
node.ReadIndex()를 통해 MsgReadIndex를 받은 raft 모듈은 leader, follower 상태에 따라 safe read index를 확인하고 ready.ReadStates를 통해 외부로 전달해는 방식이다. 유의할 점은 MsgReadIndex는 broadcast되는 것이 아니라서 모든 노드의 ready.ReadStates에서 요청한 safe read index가 전달되지 않는다.
slow follower의 경우 현재 Storage의 appliedIndex와 safe read index를 비교해서 뒤쳐져 있는 경우 오류를 응답하도록 구현할 수 있을 것 같다.
snapshot
제일 어려웠던 부분이다. triggerSnapshot 부분은 README 문서에 나와있지 않아서 코드를 읽으면서 직접 파악해 나갈 수 밖에 없었다. 스냅샷에 담길 내용은 어떤 것인지, 생성된 스냅샷은 어떻게 raft 모듈 내부로 전달되는지 스냅샷을 그냥 transport.Send()로 전송해도 되는 것인지 등등 의문을 해소한 뒤에야 구현에 들어갈 수 있었다.
trigger snaphsot
먼저 스냅샷이 생성되는 과정은 다음과 같다.
func (rn *raftNode) maybeTriggerSnapshot(applyDoneCh <-chan struct{}) {
if rn.appliedIndex-rn.snapshotIndex <= rn.snapCount { // 스냅샷을 생성할 만큼 복제로그가 쌓였는지 확인
return
}
// ...
// CommittedEntries가 모두 처리될때까지 대기
data, err := rn.getSnapshot() // 최신 CommittedEntries 까지 반영한 Storage 계층의 스냅샷 구하기
if err != nil {
log.Panic(err)
}
// MemoryStorage에 스냅샷을 저장하는 동시에 data에 Metadata를 붙여서 raftpb.Snapshot를 생성함
snapshot, err := rn.raftStorage.CreateSnapshot(rn.appliedIndex, &rn.confState, data)
if err != nil {
log.Panic(err)
}
if err := rn.saveSnap(snapshot); err != nil { // 생성한 스냅샷을 디스크에 저장
log.Panic(err)
}
// 스냅샷에 담겨서 더이상 유지하지 않아도 되는 복제 로그들 정리
// slow follower 를 위해 10K 정도는 남겨둠
// 스냅샷을 전송하는 일이 최소한으로 발생하도록 최신 로그를 조금 남겨두는 것 같음
compactIndex := uint64(1)
if rn.appliedIndex > defaultSnapshotCatchUpEntries {
compactIndex = rn.appliedIndex - defaultSnapshotCatchUpEntries
}
if err := rn.raftStorage.Compact(compactIndex); err != nil {
log.Panic(err)
}
rn.snapshotIndex = rn.appliedIndex
}
스냅샷을 생성하고, 디스크에 저장하고, 복제 로그를 정리하는 부분은 명확하게 나와있어서 흐름을 파악하기가 어렵지 않았다. 하지만 스냅샷을 생성했다고 해서 raft 모듈이 어떻게 다른 노드에게 스냅샷을 전달하게 되는지는 의문이었다.
정답은 rn.raftStorage.CreateSnapshot에 있었다.
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/raft/storage.go#L76
type MemoryStorage struct {
// ...
snapshot pb.Snapshot
// ...
}
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/raft/storage.go#L194
func (ms *MemoryStorage) CreateSnapshot(i uint64, cs *pb.ConfState, data []byte) (pb.Snapshot, error) {
// ...
// MemoryStorage 안에 스냅샷 data를 저장하고있다가 이후 raft 모듈이 스냅샷을 요청하면 반환해줌
ms.snapshot.Metadata.Index = i
ms.snapshot.Metadata.Term = ms.ents[i-offset].Term
if cs != nil {
ms.snapshot.Metadata.ConfState = *cs
}
ms.snapshot.Data = data
return ms.snapshot, nil
}
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/raft/storage.go#L166
func (ms *MemoryStorage) Snapshot() (pb.Snapshot, error) {
ms.Lock()
defer ms.Unlock()
return ms.snapshot, nil
}
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/raft/raft.go#L432
func (r *raft) maybeSendAppend(to uint64, sendIfEmpty bool) bool {
// ...
m := pb.Message{}
m.To = to
term, errt := r.raftLog.term(pr.Next - 1)
ents, erre := r.raftLog.entries(pr.Next, r.maxMsgSize)
// ...
if errt != nil || erre != nil { // send snapshot if we failed to get term or entries
// ...
m.Type = pb.MsgSnap
snapshot, err := r.raftLog.snapshot() // MemoryStorage에 저장했던 스냅샷
// ...
m.Snapshot = snapshot
// ...
pr.BecomeSnapshot(sindex)
} else {
// ...
}
r.send(m)
return true
}
위와 같이 MemoryStorage.CreateSnapshot()으로 생성한 스냅샷은 이후 raft 모듈 내부인 raft.maybeSendAppend()에서 raftpb.Message에 담겨 다른 노드로 전송되게 된다.
send snaphsot
raft 모듈 내부 알고리즘에 의해 다른 노드로 스냅샷을 전송해야 하는 경우에 전송할 스냅샷은 ready.Messages에 담겨있고, raft main loop에서 우리가 직접 다른 노드로 전송해야 한다.
외부에서 생성한 스냅샷이 어떻게 raft 모듈 내부에서 처리되고 ready.Messages에 담기는지는 앞에 나와있다.
// ...
for {
select {
case <-ticker.C:
rn.node.Tick()
case rd := <-rn.node.Ready():
// ..
// 만약 다른 노드로 스냅샷을 보내야 하는 경우
// rd.Messages 속에 Message.Type == raftpb.MsgSnap인 스냅샷 메시지가 담겨있음
rn.transport.Send(rn.processMessage(rd.Messages))
// ...
case <-rn.transport.ErrorC:
return
case <-rn.ctx.Done():
return
}
}
// ...
etcd의 경우 별도 처리 로직을 위해 다른 고루틴에서 스냅샷 관련 작업을 한뒤에 transport.SendSnapshot을 통해 다른 노드로 전송한다. 반면에 raftexample에서는 그냥 transport.Send로 전송해버린다.
그래서 rafthttp를 사용할 때 스냅샷 전송시 따로 신경써야 하는 부분이 있는지 찾아보았다. 결과적으로는 transport.Send도 스냅샷 전송과 관련해서 raft.ReportUnreachable, raft.ReportSnapshot 같은 작업을 처리해주긴 한다. 하지만 rafthttp.snapshotSender(transport.SendSnapshot)을 이용하지는 않아서 동작에 약간의 차이가 있다.
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/server/etcdserver/api/rafthttp/transport.go#L175
func (t *Transport) Send(msgs []raftpb.Message) {
for _, m := range msgs {
// ...
p, pok := t.peers[to]
g, rok := t.remotes[to]
// ...
if pok {
// ...
p.send(m) // peer -> pipeline
continue
}
if rok {
g.send(m) // pipeline
continue
}
// ...
}
}
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/server/etcdserver/api/rafthttp/peer.go#L236
func (p *peer) send(m raftpb.Message) {
// ...
writec, name := p.pick(m)
select {
case writec <- m:
// ...
}
}
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/server/etcdserver/api/rafthttp/peer.go#L337
func (p *peer) pick(m raftpb.Message) (writec chan<- raftpb.Message, picked string) {
// ...
if isMsgSnap(m) {
return p.pipeline.msgc, pipelineMsg
}
// ...
return p.pipeline.msgc, pipelineMsg
}
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/server/etcdserver/api/rafthttp/pipeline.go#L93
func (p *pipeline) handle() {
// ...
for {
select {
case m := <-p.msgc:
// ...
err := p.post(pbutil.MustMarshal(&m))
// ...
if err != nil {
// ...
p.raft.ReportUnreachable(m.To)
if isMsgSnap(m) {
p.raft.ReportSnapshot(m.To, raft.SnapshotFailure)
}
// ...
continue
}
// ...
if isMsgSnap(m) {
p.raft.ReportSnapshot(m.To, raft.SnapshotFinish)
}
// ...
case <-p.stopc:
return
}
}
}
transport.Send가 스냅샷도 잘 처리해주는 것을 확인해서 따로 수정하지 않았다.
apply snaphost
다른 노드로부터 받은 스냅샷을 Storage에 적용해야 하는 경우 해당 스냅샷은 ready.Snapshot에 담겨 raft main loop로 전달된다.
Transport 계층을 통해 받은 스냅샷이 ready.Snapshot에 담기는 과정은 다음과 같다.
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/raft/raft.go#L1518
func (r *raft) handleSnapshot(m pb.Message) {
// ...
if r.restore(m.Snapshot) {
// ...
r.send(pb.Message{To: m.From, Type: pb.MsgAppResp, Index: r.raftLog.lastIndex()})
}
// ...
}
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/raft/log.go#L336
func (r *raft) restore(s pb.Snapshot) bool {
// ...
r.raftLog.restore(s)
// ...
}
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/raft/log_unstable.go#L115
func (u *unstable) restore(s pb.Snapshot) {
// ...
u.snapshot = &s
}
// https://github.com/etcd-io/etcd/blob/v3.6.0-alpha.0/raft/node.go#L564
func newReady(r *raft, prevSoftSt *SoftState, prevHardSt pb.HardState) Ready {
rd := Ready{
Entries: r.raftLog.unstableEntries(),
CommittedEntries: r.raftLog.nextEnts(),
Messages: r.msgs,
}
// ...
if r.raftLog.unstable.snapshot != nil {
rd.Snapshot = *r.raftLog.unstable.snapshot
}
// ...
return rd
}
전달받은 스냅샷은 디스크에 저장되지 않은 상태로 raftLog.unstable.snapshot에 임시로 저장해뒀다가 이후 ready가 생성될 때 외부로 전달된다.
따라서 ready.Snapshot을 전달받은 raft main loop는 스냅샷을 디스크에 저장한 뒤에 Storage에 적용해야 하는 것이다.
// ...
for {
select {
case <-ticker.C:
rn.node.Tick()
case rd := <-rn.node.Ready():
if !raft.IsEmptySnap(rd.Snapshot) {
rn.saveSnap(rd.Snapshot) // 디스크에 저장
}
// ...
if !raft.IsEmptySnap(rd.Snapshot) {
rn.raftStorage.ApplySnapshot(rd.Snapshot)
rn.publishSnapshot(rd.Snapshot) // Storage에 적용
}
// ...
case <-rn.transport.ErrorC:
return
case <-rn.ctx.Done():
return
}
}
// ...
snapshot 흐름 정리
raft main loop 안에는 스냅샷 생성, 수신/저장/적용, 전송이 모두 섞여있어서 흐름을 파악하기 너무 어렵다. 대략적으로 각 흐름을 그림으로 정리해보았다.
- 초록: 스냅샷 생성
- 분홍: 스냅샷 전송
- 보라: 스냅샷 수신
- 주황: 스냅샷 저장 및 적용

결과
클러스터 생성
다음과 같이 3개의 노드로 클러스터를 생성했다.
// node1
# ./godis cluster --id 1 \
--listen-client http://0.0.0.0:6379 \
--listen-peer http://127.0.0.1:6300 \
--initial-cluster 1@http://127.0.0.1:6300,2@http://127.0.0.1:16300,3@http://127.0.0.1:26300 \
--waldir ./node-1/wal --snapdir ./node-1/snap
// node2
# ./godis cluster --id 2 \
--listen-client http://0.0.0.0:6380 \
--listen-peer http://127.0.0.1:16300 \
--initial-cluster 1@http://127.0.0.1:6300,2@http://127.0.0.1:16300,3@http://127.0.0.1:26300 \
--waldir ./node-2/wal --snapdir ./node-2/snap
// node3
# ./godis cluster --id 3 \
--listen-client http://0.0.0.0:6381 \
--listen-peer http://127.0.0.1:26300 \
--initial-cluster 1@http://127.0.0.1:6300,2@http://127.0.0.1:16300,3@http://127.0.0.1:26300 \
--waldir ./node-3/wal --snapdir ./node-3/snap
좌: node1에 연결, 우: node2에 연결

새로운 노드 참가
// client
# cluster meet 4 http://127.0.0.1:36300
// node4
# ./godis cluster --id 4 \
--listen-client http://0.0.0.0:6382 \
--listen-peer http://127.0.0.1:36300 \
--discovery http://127.0.0.1:6300,http://127.0.0.1:16300 \
--waldir ./node-4/wal --snapdir ./node-4/snap --join
좌: node1에 연결, 우: node4에 연결

마치며
확실히 2년전에 코드를 분석했던 때와는 다르게 직접 사용하는 것을 목적으로 코드를 다시 읽다보니 디테일한 부분까지 생각해보게 되어서 etcd raft 모듈에 대한 이해가 좀더 깊어졌던 것 같습니다. 아주 간소한 버전이고 부족함도 많지만 직접 분산 환경의 데이터베이스를 구현해본 것에 큰 보람을 느낍니다.
글을 쓰기 전에는 raft 모듈을 사용해보면서 느꼈던 부분들을 모두 녹아내려 했었는데 필력이 부족해서 모두 담지 못한 것 같아 아쉽습니다. 뭔가 어중간한 글이 되어버렸지만 etcd를 분석해보고자 하는 분이나 raft 모듈을 사용하보고자 하는 분들께 도움이 되었으면 좋겠습니다. 부족한 글을 읽어주셔서 감사합니다.